시각 패턴 중심 기존 AI 한계 극복…‘물리적으로 일관된 생성 AI’ 가능성 제시
KAIST(총장 이광형)는 전산학부 오태현 교수 연구팀이 POSTECH(총장 김성근), 소니 AI(Sony AI) 공동 연구진과 함께 영상 속 물리적 상황을 이해해 보다 현실감 있는 소리를 생성하는 인공지능(AI) 기술 ‘파바스(PAVAS·Physics-Aware Video-to-Audio Synthesis)’를 개발했다고 5월 26일 밝혔다.
영화 ‘쥬라기 공원’에서 거대한 공룡이 걸어오는 장면을 보면 사람들은 자연스럽게 땅이 울리는 듯한 묵직한 저주파음을 떠올린다. 이는 인간이 단순히 사물의 형태뿐 아니라 크기와 무게, 움직임의 속도 같은 물리적 특성까지 함께 고려해 소리를 예측하기 때문이다. 하지만 기존 영상-음향 생성 AI는 화면 속 사물의 형태나 장면 정보에 주로 의존해 소리를 생성해, 무게나 속도에 따라 달라지는 물리적 특성까지는 충분히 반영하지 못했다.
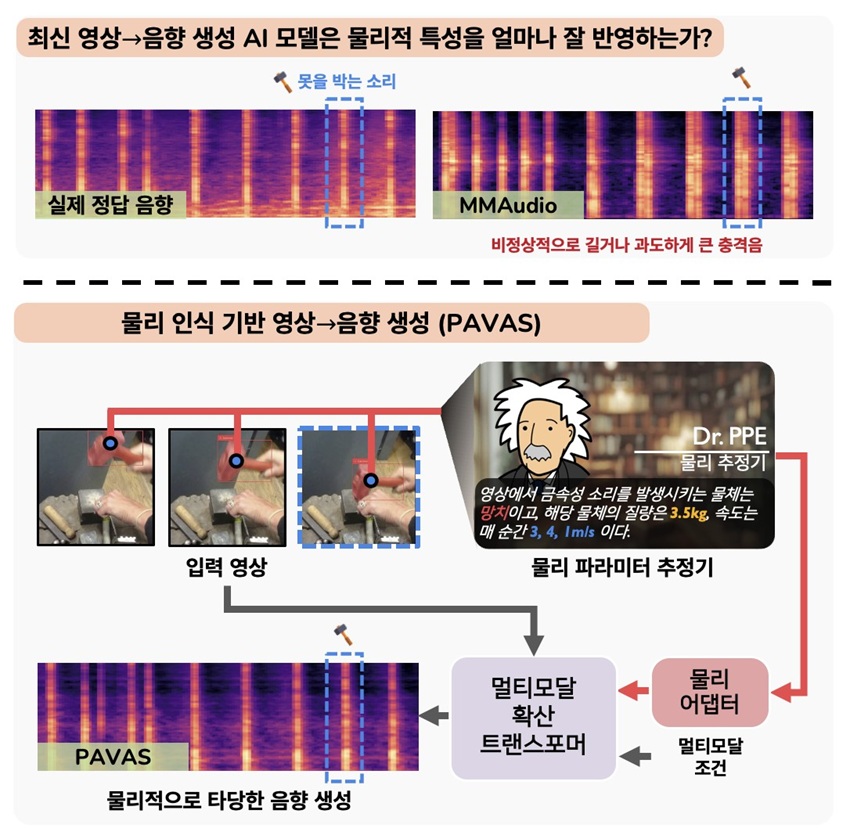
이번 기술의 핵심은 영상 속 물체의 질량과 속도 등 눈에 보이지 않는 물리 정보를 AI가 스스로 추론하도록 설계됐다는 점이다. 일반적인 영상에는 물체의 정확한 무게나 속도가 숫자로 제시되지 않지만, 연구팀은 AI가 주변 환경과 움직임의 맥락을 분석해 이를 추정하고, 그 결과를 소리 생성 과정에 반영하도록 했다.
즉, 단순히 ‘무엇이 보이는지’를 인식하는 수준을 넘어, ‘왜 이런 소리가 발생해야 하는지’에 대한 물리적 원인까지 AI가 이해하도록 만든 것이다.
기술 검증 결과, 연구팀의 AI는 물체 간 충돌이나 타격 등 물리적 상호작용이 발생하는 장면에서 실제 환경과 매우 유사한 소리를 생성했다. 특히 물체의 질량과 속도가 달라질 때 소리의 크기와 음색도 자연스럽게 변화하는 등 보다 현실감 있는 음향을 구현했다.
최근에는 영상과 오디오를 동시에 생성하는 생성형 AI 기술이 빠르게 발전하고 있다. 대표적으로 구글의 ‘비오(Veo) 3’, 바이트댄스의 ‘시댄스(Seedance) 2.0’ 등이 있다. 그러나 실제 영화·광고·게임 제작 현장에서는 새로운 영상을 생성하는 것보다 기존 영상에 장면에 맞는 효과음을 추가하거나 음향을 보완하는 후반 작업 수요가 훨씬 크다.
기존 상용 AI 모델들이 영상과 오디오를 함께 생성하는 데 집중했다면, 파바스는 영상 속 객체의 움직임과 충돌 특성을 분석해 장면과 정밀하게 맞아떨어지는 현실적인 효과음을 생성한다는 점에서 차별성을 가진다는 설명이다.
연구팀은 이번 기술이 ‘물리적으로 일관된 생성 AI(Physical AI)’ 분야의 새로운 가능성을 제시했다고 설명했다. 물리적으로 일관된 생성 AI는 단순히 그럴듯한 결과를 만드는 수준을 넘어, 현실 세계의 물리 법칙과 인과관계까지 이해하는 AI를 의미한다는 것이다.
향후 이 기술은 콘텐츠 음향 제작 자동화는 물론, 증강현실(AR)·가상현실(VR) 콘텐츠, 메타버스, 로보틱스 시뮬레이션 등 다양한 분야에서 더욱 몰입감 있는 사용자 경험을 제공할 수 있을 것으로 기대된다고 KAIST 측은 전했다.
오태현 교수는 “기존 생성 AI가 데이터와 모델 규모를 키우는 방식으로 발전해 왔다면, 이번 연구는 AI가 물리량과 인과관계를 직접 이해하도록 설계했다는 점에서 의미가 있다”며, “향후 텍스트·영상·음성 등 다양한 정보를 동시에 이해하고 처리하는 차세대 멀티모달 AI의 핵심 기반 기술로 확장될 수 있을 것”이라고 말했다.
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>







